

Why Synthetic Data?


Compliance without Compromise
Regulations like GDPR and HIPAA severely limit the use of production data outside controlled environments. Synthetic data allows innovation without breaching compliance boundaries.


How it Works
Assess the Domain
We evaluate domain data and identify privacy risks by ensuring every generation run starts with compliance in mind.
Profile the Data
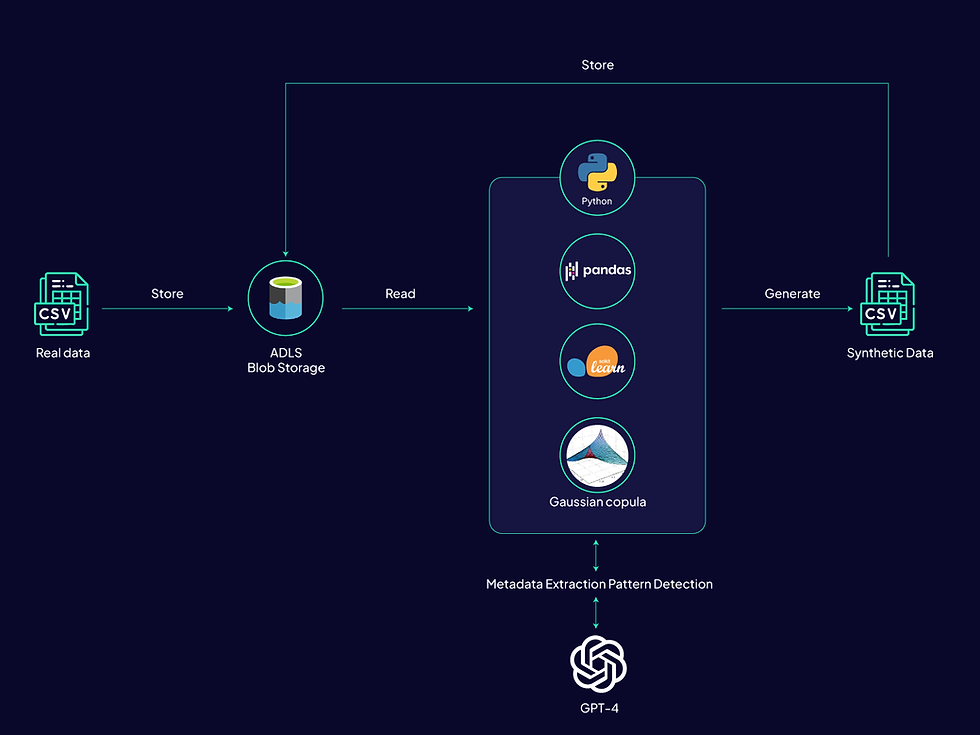
We analyse distributions and gaps to capture the true structure of datasets before generation.
Generate Synthetic Records
Using GAN and LLM-based models, we create synthetic datasets that replicate real patterns while eliminating sensitive identifiers.
Validate for Safety and Utility
Every dataset undergoes leakage checks, statistical comparisons and ML model benchmarks to confirm both realism and privacy.
Publish with Governance
Synthetic data is delivered in Delta format and registered in Unity Catalog for lineage and traceability.
Refresh with Automation
Pipelines keep synthetic datasets continuously updated on demand or scheduled to ensure safe and current data.

Flexible Generation Models
Including CTGAN and DP-CTGAN for tabular data, TimeGAN for time-series and LLM-based approaches for text and ensuring the right engine for every dataset.

Industry-Ready Templates
Pre-configured for finance, healthcare, retail and manufacturing, helping teams accelerate adoption without starting from scratch.

Privacy Assurance
Built-in techniques such as k-anonymity, differential privacy and leakage detection ensre sensitive information is never exposed.

Utility
Validation
Synthetic records are benchmarked against ML model accuracy baselines to confirm they perform close to real-world data.
Watch Accelerator in Action


